





Tổng Quan về Kafka
Cluster Kafka, bạn có biết chúng ta tiêu thụ bao nhiêu dữ liệu mỗi ngày không? Theo báo cáo của Gartner, chúng ta tiêu thụ khoảng 1,8 GB dữ liệu mỗi ngày cho các hoạt động hàng ngày của mình. Thách thức mà chúng tôi gặp phải ở đây là thu thập và phân tích dữ liệu khổng lồ. Vì vậy, chúng tôi cần một hệ thống nhắn tin mạnh mẽ có thể thực hiện các nhiệm vụ phân tích dữ liệu và thân thiện với người dùng.
Vâng, bạn nói đúng, chúng ta đang nói về “Apache Kafka”, một hệ thống nhắn tin vùng chứa dịch vụ đăng ký được xuất bản để xử lý việc phân phối dữ liệu giữa nhiều ứng dụng. Trong bài đăng Apache Kafka này, chúng tôi sẽ giải thích các khái niệm cơ bản để giúp độc giả nâng cao bộ kỹ năng của họ trong Apache Kafka. Bắt đầu nào;
Apache Kafka là gì ?
Apache Kafka là một hệ thống nhắn tin đăng ký được xuất bản được thiết kế để phân phối dữ liệu trên toàn hệ thống. Đây là một hệ thống môi giới tin nhắn phổ biến hoạt động tốt và mang lại lợi ích tối đa so với các hệ thống tin nhắn truyền thống khác. Hệ thống tin nhắn này có nhiều tính năng nâng cao khác nhau như phân vùng tích hợp, khả năng chịu lỗi vốn có và sao chép, giúp nó phù hợp với các ứng dụng kinh doanh xử lý tin nhắn quy mô lớn.
Ứng dụng phân tán trong nhắn tin Kafka được xây dựng trên kiến trúc xếp hàng tin nhắn đáng tin cậy. Trong Kafka, có hai loại mẫu tin nhắn; một là điểm tới điểm và một là đăng ký xuất bản. Hầu hết các ứng dụng hệ thống nhắn tin gần đây đều sử dụng loại thuê bao Xuất bản. Hệ thống Apache Kafka Server được xây dựng dựa trên dịch vụ đồng bộ hóa Zookeeper và tích hợp tốt với các bộ chứa dịch vụ Apache.
Apache Kafka hoạt động như thế nào ?
Trong phần này, chúng tôi sẽ giải thích quy trình làm việc hoàn chỉnh của Apache Kafka và các thành phần của nó. Hình ảnh sau đây minh họa tính chất công việc tổng thể của Apache Kafka:
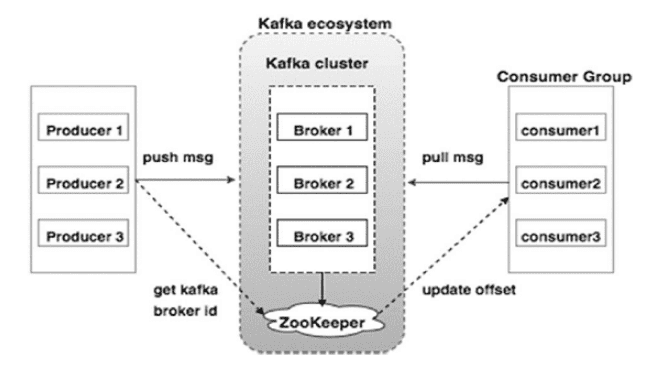
Kiến trúc quy trình làm việc của nó bao gồm bốn thành phần chính, chẳng hạn như:
- Nhà môi giới
- Người giữ vườn thú
- Nhà sản xuất
- Người tiêu dùng
Hãy để tôi giải thích chúng một cách ngắn gọn:
Nhà môi giới : thành phần môi giới trong kiến trúc Kafka chủ yếu được sử dụng để duy trì cân bằng tải. Quan trọng nhất, các nhà môi giới Kafka không có quốc tịch và sử dụng những người trông coi vườn thú để duy trì trạng thái cụm của họ. Một trạng thái môi giới có thể xử lý hàng trăm/hàng nghìn lượt đọc hoặc ghi mỗi giây.
Zookeeper : Zookeeper ở Kafka được dùng để quản lý và điều phối các nhà môi giới kafka. Loại dịch vụ này gửi thông báo đến nhà sản xuất và người tiêu dùng về sự hiện diện hay thất bại của nhà môi giới mới trong hệ sinh thái Kafka. Theo thông báo mà người quản lý vườn thú nhận được; cả nhà sản xuất và người tiêu dùng đều đưa ra quyết định sâu hơn và bắt đầu phối hợp với các nhà môi giới khác.
Nhà sản xuất : nhiệm vụ chính của nhà sản xuất là đẩy dữ liệu đến nhà môi giới. Khi có sẵn một nhà môi giới mới, nhà sản xuất sẽ tự động tìm kiếm nó và gửi tin nhắn đến nhà môi giới mới. Họ không bao giờ chờ đợi sự xác nhận và gửi tin nhắn nhanh nhất có thể.
Người tiêu dùng : chúng tôi biết rằng các nhà môi giới Kafka không có trạng thái quốc tịch nên người tiêu dùng đóng vai trò quan trọng trong việc duy trì các thông điệp được sử dụng bởi các phân vùng bù đắp khác (một nhóm nhà môi giới khác). Nếu người tiêu dùng nhận được bất kỳ xác nhận nào về việc sử dụng tin nhắn; nó có nghĩa là người tiêu dùng đã sử dụng tất cả các tin nhắn trước đó. Người tiêu dùng cũng gửi yêu cầu kéo tới các nhà môi giới để sử dụng byte dữ liệu đệm. Người tiêu dùng có thể bỏ qua hoặc tua lại tại bất kỳ điểm nào của phân vùng chỉ bằng cách cung cấp giá trị bù.
Lợi ích của Apache Kafka
Sau đây là những lợi ích chính của Apache Kafka:
Thứ tự tin nhắn: Apache Kafka cung cấp thứ tự tin nhắn dựa trên các phân vùng trong quy trình làm việc. Do đó, các tin nhắn được gửi đến từng chủ đề bằng cách sử dụng các phím tin nhắn.
Cung cấp tính năng nhắn tin trọn đời: Apache Kafka là một nhật ký, có nghĩa là các tin nhắn luôn ở đó. Tin nhắn có thể quản lý việc này bằng cách chỉ định chính sách lưu giữ tin nhắn.
Đảm bảo giao hàng: Hệ sinh thái Apache Kafka duy trì trật tự bên trong một phân vùng. Trong một phân vùng, Kafka đảm bảo rằng toàn bộ lô tin nhắn sẽ bị lỗi hoặc được chuyển đi.
Hiệu suất: Hiệu suất cao hơn do ngữ nghĩa thông điệp đơn giản hơn và sử dụng các giao thức độc quyền.
Độ tin cậy ở mức độ cao: Hệ thống nhắn tin Apache Kafka là hệ thống phân tán và cũng giúp ngăn ngừa lỗi.
Khả năng mở rộng: Hệ thống nhắn tin Apache Kafka có thể mở rộng quy mô rất dễ dàng, do đó không cần thời gian ngừng hoạt động.
Độ bền: Hệ thống thông báo Apache Kafka sử dụng tùy chọn “nhật ký cam kết được phân phối” cho phép các thông báo được liên tục trên đĩa một cách nhanh chóng. Do đó nó là một hệ thống tin nhắn bền hơn.
Trong bài đăng này, chúng tôi sẽ giải thích cách cài đặt Apache Kafka trên Ubuntu 20.04.
Cài đặt Cluster Kafka
Cài đặt Java
Apache Kafka là một ứng dụng dựa trên Java. Vì vậy, Java phải được cài đặt trên hệ thống của bạn. Nếu chưa được cài đặt, bạn có thể cài đặt nó bằng cách chạy lệnh sau:
apt-get install default-jdk -ySau khi Java được cài đặt, hãy xác minh cài đặt Java bằng lệnh sau:
java --versionBạn sẽ nhận được kết quả đầu ra sau:
openjdk 11.0.13 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)Cài đặt Apache Kafka
Trước khi bắt đầu, bạn nên tạo một người dùng chuyên dụng để chạy Apache Kafka. Bạn có thể tạo nó bằng lệnh sau:
adduser kafkaTiếp theo, thêm người dùng Kafka vào nhóm sudo bằng lệnh sau:
adduser kafka sudoTiếp theo, đăng nhập với tư cách người dùng Kafka và tải xuống phiên bản mới nhất của Apache Kafka bằng lệnh sau:
su - kafka<br>wget https://dlcdn.apache.org/kafka/2.7.2/kafka-2.7.2-src.tgzSau khi quá trình tải xuống hoàn tất, hãy giải nén tệp đã tải xuống bằng lệnh sau:
tar -xvzf kafka-2.7.2-src.tgz<br>mv kafka-2.7.2-src kafkaTiếp theo, thoát khỏi người dùng Kafka bằng lệnh sau:
exitTiếp theo, bạn cũng sẽ cần cài đặt Gradle vào hệ thống của mình. Bạn có thể cài đặt nó bằng lệnh sau:
cd /home/kafka/kafka<br>./gradlew jar -PscalaVersion=2.13.3Tiếp theo, đặt quyền sở hữu phù hợp cho thư mục Kafka:
chown -R kafka:kafka /home/kafka/kafkaTạo tệp đơn vị Systemd cho Kafka và Zookeeper
Tiếp theo, bạn sẽ cần tạo tệp dịch vụ systemd cho cả Zookeeper và Kafka. Đầu tiên, tạo tệp dịch vụ Zookeeper bằng lệnh sau:
nano /etc/systemd/system/zookeeper.serviceThêm các dòng sau:
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetLưu và đóng tệp sau đó tạo tệp dịch vụ systemd cho Kafka bằng lệnh sau:
nano /etc/systemd/system/kafka.serviceThêm các dòng sau:
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetLưu và đóng tệp sau đó tải lại daemon systemd bằng lệnh sau:
systemctl daemon-reloadTiếp theo, khởi động và kích hoạt dịch vụ Apache Kafka bằng lệnh sau:
systemctl enable --now kafkaBây giờ bạn có thể kiểm tra trạng thái của dịch vụ Apache Kafka và Zookeeper bằng lệnh sau:
systemctl status kafka zookeeperBạn sẽ nhận được kết quả đầu ra sau:
● kafka.service
Loaded: loaded (/etc/systemd/system/kafka.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-01-19 06:27:07 UTC; 1min 9s ago
Main PID: 6576 (sh)
Tasks: 69 (limit: 2353)
Memory: 339.2M
CGroup: /system.slice/kafka.service
├─6576 /bin/sh -c /home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kaf>
└─6581 java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvo>
● zookeeper.service
Loaded: loaded (/etc/systemd/system/zookeeper.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-01-19 06:27:07 UTC; 1min 9s ago
Main PID: 6575 (java)
Tasks: 27 (limit: 2353)
Memory: 59.5M
CGroup: /system.slice/zookeeper.service
└─6575 java -Xmx512M -Xms512M -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGC>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,772] INFO Created server with tickTime 3000 minSessionTimeou>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,801] INFO Using org.apache.zookeeper.server.NIOServerCnxnFac>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,814] INFO Configuring NIO connection handler with 10s sessio>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,828] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.z>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,875] INFO zookeeper.snapshotSizeFactor = 0.33 (org.apache.zo>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,886] INFO Snapshotting: 0x0 to /tmp/zookeeper/version-2/snap>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,896] INFO Snapshotting: 0x0 to /tmp/zookeeper/version-2/snap>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,958] INFO PrepRequestProcessor (sid:0) started, reconfigEnab>
Jan 19 06:27:09 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:09,971] INFO Using checkIntervalMs=60000 maxPerMinute=10000 (or>
Jan 19 06:27:10 ubuntu2004 zookeeper-server-start.sh[6575]: [2022-01-19 06:27:10,742] INFO Creating new log file: log.1 (org.apache.zookeeper>
lines 1-31/31 (END)Cài đặt Trình quản lý Cluster cho Apache Kafka
CMAK là một công cụ nguồn mở để quản lý và giám sát các dịch vụ do Yahoo phát triển. Đầu tiên, tải xuống bằng lệnh sau:
apt-get install git -y
git clone https://github.com/yahoo/CMAK.gitSau khi quá trình tải xuống hoàn tất, hãy chỉnh sửa tệp cấu hình CMAK:
nano ~/CMAK/conf/application.confThay đổi các dòng sau:
kafka-manager.zkhosts="kafka-manager-zookeeper:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
cmak.zkhosts="localhost:2181"
cmak.zkhosts=${?ZK_HOSTS}Lưu và đóng tệp sau đó điều hướng đến thư mục CMAK và tạo tệp zip để triển khai ứng dụng:
cd ~/CMAK
./sbt clean distBạn sẽ nhận được kết quả đầu ra sau:
[info] Compilation completed in 16.955s.
model contains 640 documentable templates
[info] Main Scala API documentation successful.
[info] Compiling 136 Scala sources and 2 Java sources to /root/CMAK/target/scala-2.12/classes ...
[info] LESS compiling on 1 source(s)
[success] All package validations passed
[info] Your package is ready in /root/CMAK/target/universal/cmak-3.0.0.5.zip
[success] Total time: 414 s (06:54), completed Jan 19, 2022, 6:40:12 AMTiếp theo, điều hướng đến thư mục ~/CMAK/target/universal và giải nén tệp zip:
cd ~/CMAK/target/universal
unzip cmak-3.0.0.5.zipTiếp theo, thay đổi thư mục thành thư mục đã giải nén và chạy tệp nhị phân cmak:
cd cmak-3.0.0.5
bin/cmakNếu mọi thứ đều ổn, bạn sẽ nhận được kết quả sau:
2022-01-19 06:41:18,495 - [INFO] k.m.a.KafkaManagerActor - Started actor akka://kafka-manager-system/user/kafka-managerlistener...
2022-01-19 06:41:18,551 - [INFO] k.m.a.KafkaManagerActor - Adding kafka manager path cache listener...
2022-01-19 06:41:19,149 - [INFO] play.api.Play - Application started (Prod)
2022-01-19 06:41:19,572 - [INFO] k.m.a.KafkaManagerActor - Updating internal state...
2022-01-19 06:41:20,665 - [INFO] p.c.s.AkkaHttpServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000Tại thời điểm này, CMAK được khởi động và lắng nghe trên cổng 9000 .
Truy cập Trình quản lý cụm Kafka
Bây giờ bạn có thể truy cập Trình quản lý Cluster bằng URL http://your-server-ip:9000 . Bạn sẽ thấy trang sau:
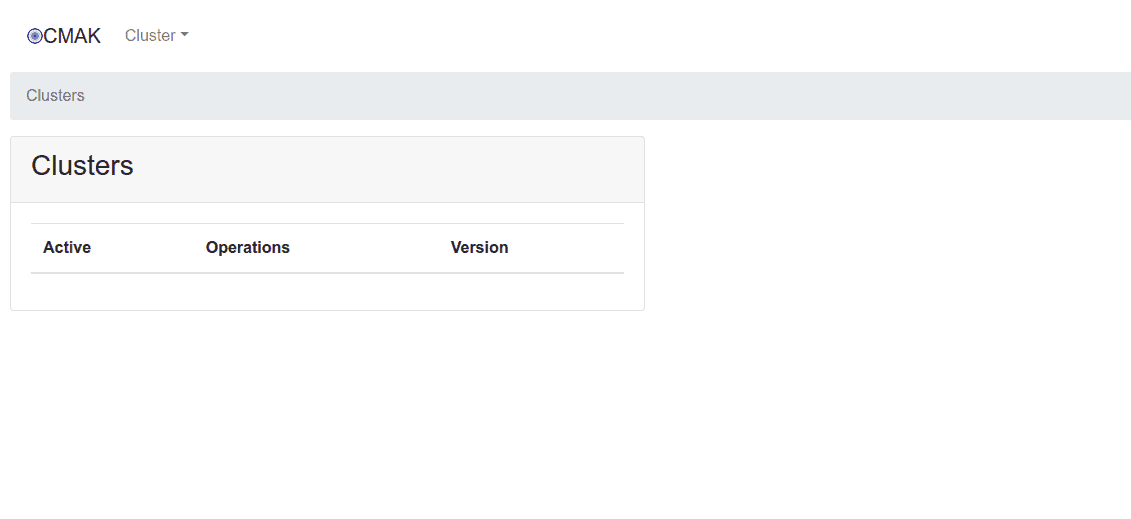
Nhấn vào Cluster => Add Cluster để thêm cluster. Bạn sẽ thấy trang sau:
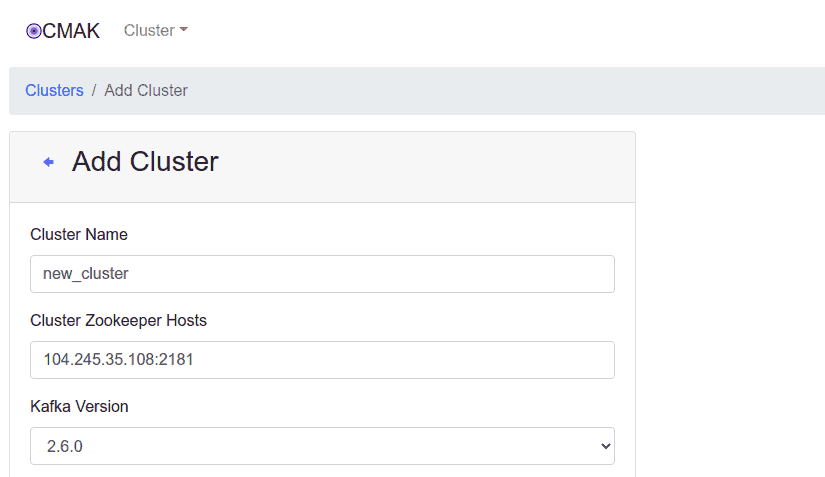
Cung cấp thông tin cụm của bạn và nhấp vào nút Lưu . Bạn sẽ thấy trang sau:
Tiếp theo, thay đổi thư mục thành Kafka và tạo một chủ đề mẫu bằng lệnh sau:
cd /home/kafka/kafka/
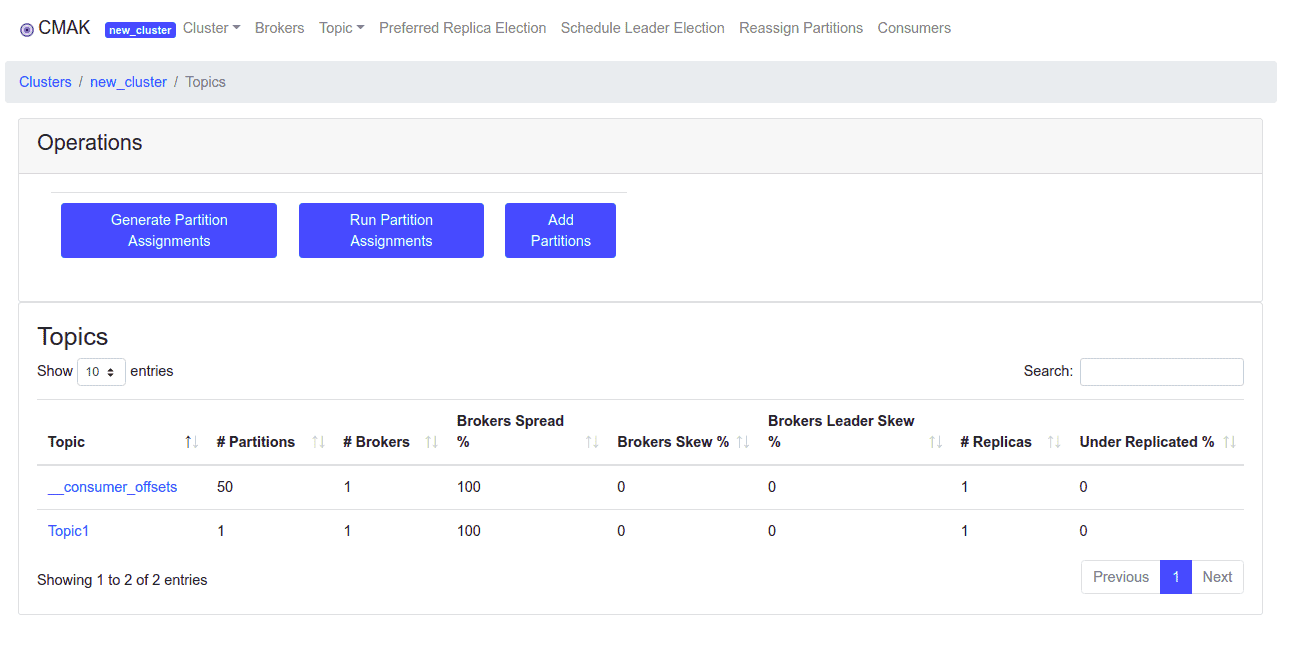
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic1Bây giờ, hãy vào cluster view sau đó nhấn Topic => List . Bạn sẽ thấy chủ đề tạo của mình trên trang sau :
Kết Bài
Trong hướng dẫn này, bạn đã học cách cài đặt để xử lý luồng và môi giới tin nhắn trên hệ thống Ubuntu 22.04. Bạn cũng đã tìm hiểu cấu hình cơ bản trên hệ thống Ubuntu. Ngoài ra, bạn cũng đã học cách vận hành cơ bản bằng cách sử dụng Apache Kafka Nhà sản xuất và Người tiêu dùng. Và cuối cùng, bạn cũng đã học cách truyền trực tuyến các tin nhắn hoặc sự kiện từ một tệp tới Apache Kafka.
Add Comment