





How to Create a Kubernetes Cluster with AWS CLI
Elastic Kubernetes Service (EKS) is a managed Kubernetes service that is hosted on AWS.
The main reason for using EKS is to remove the burden of managing pods, nodes, etc. Running Kubernetes in AWS currently requires a great deal of technical expertise and often falls outside the wheelhouse of many organizations. With EKS, the required infrastructure is managed by Amazon’s “in-house” team, leaving users with a fully managed Kubernetes engine that can be used either via an API or standard kubectl tooling.
EKS will support all Kubernetes features, including namespaces, security settings, resource quotas & tolerations, deployment strategies, autoscalers, and more. EKS will allow you to run your own control plane, but also integrates with AWS IAM so you can maintain your own access control to the API.
EKS was built on top of Amazon’s existing “Kubernetes—as-a-Service” solution called Elastic Container Service for Kubernetes (EKS) is an AWS-managed service that simplifies the deployment, management, and operation of Kubernetes clusters in the AWS Cloud.
If you are running Kubernetes on AWS, you are responsible for managing the control plane (i.e. master nodes & worker nodes). You also have to make sure that api-server is highly available and fault-tolerant, etc.
EKS took the burden of managing the control plane away from you, by doing that, you are now able to focus on running your Kubernetes workloads. It is most commonly used for stateless applications like microservices since the control plane is managed by Amazon (EKS).
In this guide, we will leam how to create a Kubernetes cluster on AWS with EKS. You will learn how to create an administrative user for your Kubernetes cluster. You will also learn how to deploy an app to the cluster. Finally, you will test your cluster to ensure that everything is working properly.
Let’s get started!
Prerequisites
- An AWS account.
- The article assumes that you are familiar with Kubernetes and AWS. If you are not, please take some time to go through the documentation on both before starting this guide.
Creating an Admin User with Permissions
Let’s start with creating an admin user for your cluster.
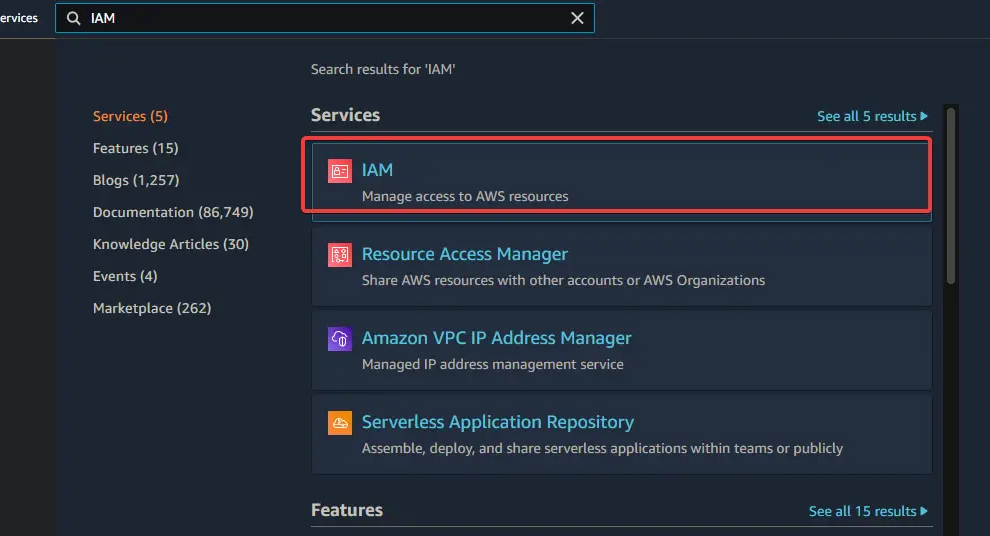
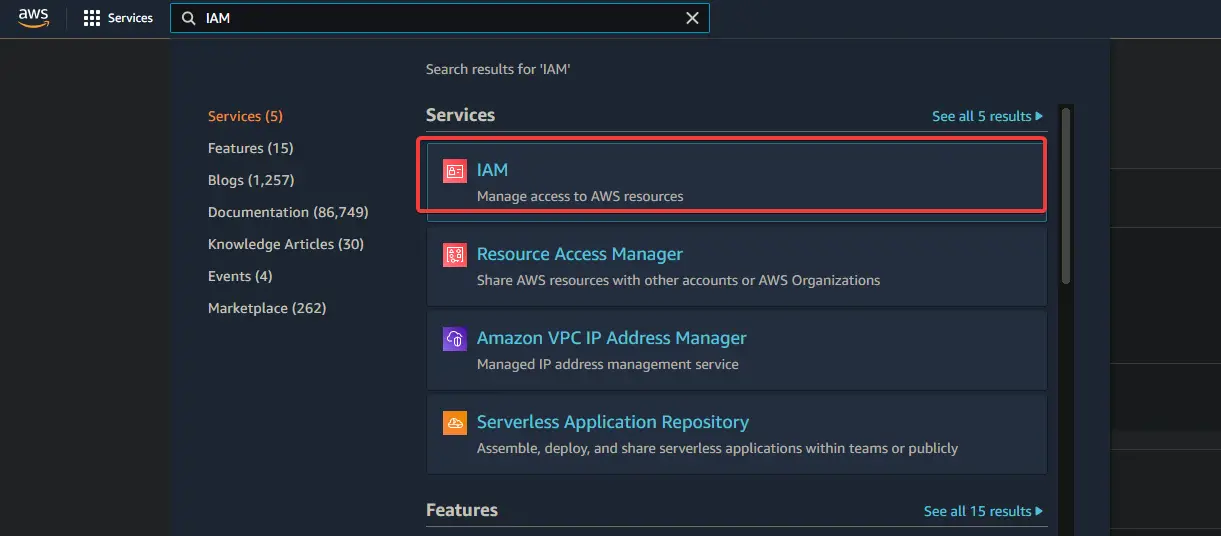
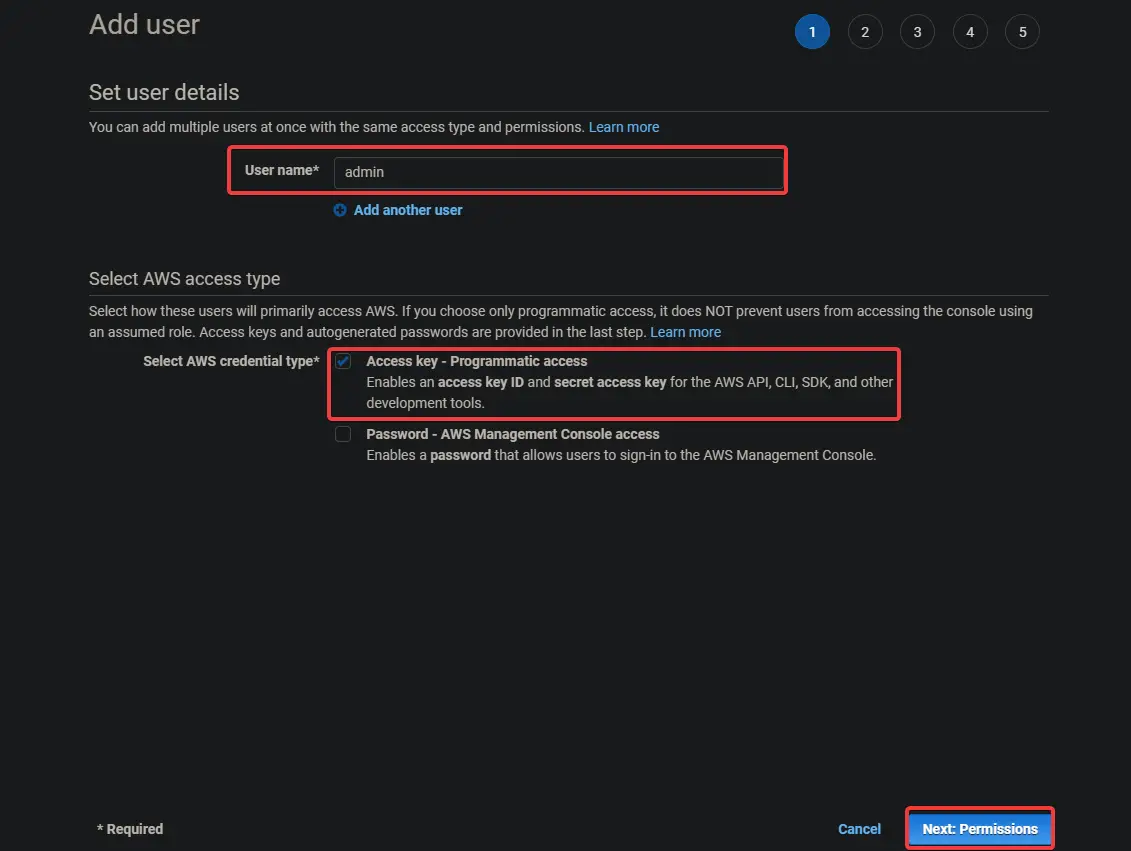
1. Log in to your AWS console and go to IAM. Click Users > Add Users.
2. On the next screen, provide a user name like admin. Select Access key – Programmatic access. Click on Next: Permissions
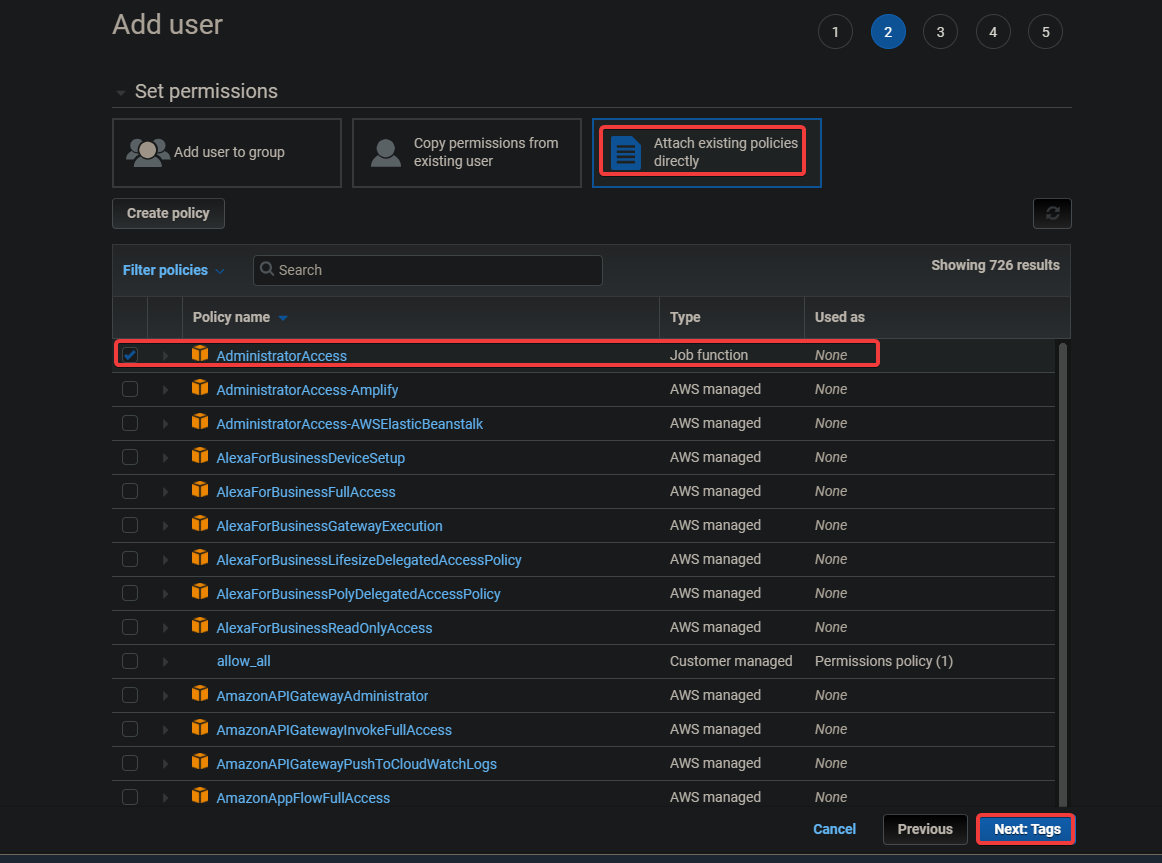
3. On the next screen, select Attach existing policies directly. Click on AdministratorAccess. Click on Next: Tags.
The AdministratorAccess policy is a built-in policy with Amazon Elastic Container Service (ECS). It provides full access to all ECS resources and all actions in the ECS console. The main benefit of this policy is that we do not need to create or manage an additional user with extra privileges for accessing the AWS EKS service.
Your admin user can create EC2 instances, CloudFormation stacks, S3 buckets, etc. You should be very careful about who you give this kind of access to.
3. On the next screen, click on Next: Review
4. On the next screen, click on Create user.
5. On the next screen, you will get a green Success message. The Access key ID and
Secret access keys are also displayed in this screen. You will need these keys to configure your CLI tools later, so note down these keys to somewhere else.
Creating an EC2 Instance
Now that you have created the administrative user , let’s create an EC2 instance to use as your Kubernetes master node.
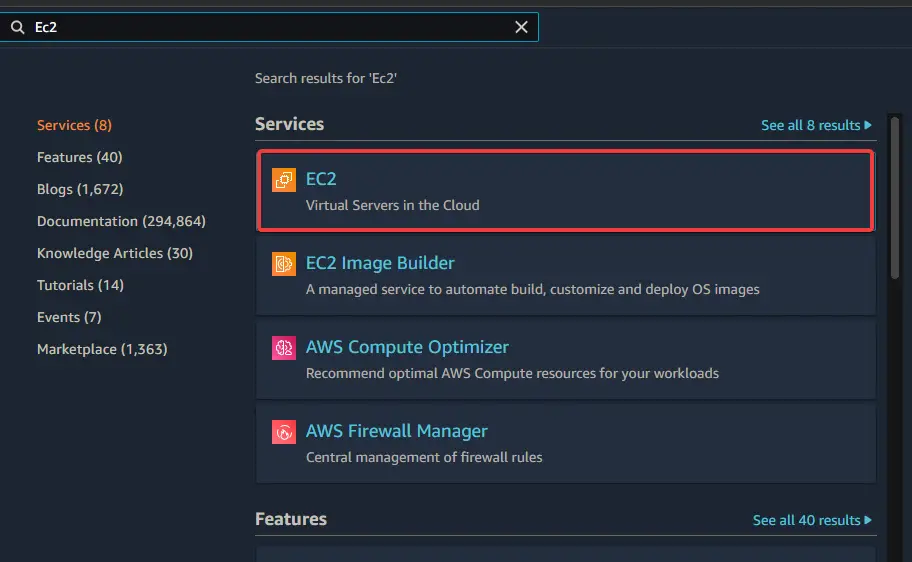
1. Type EC2 into the search box. Click on the EC2 link. Click on Launch instance.
2. Select the Amazon Linux 2 AMI (HVM) for your EC2 instance. We will be using this Amazon Linux AMI to make it easy to install Kubernetes and other needed tools later, such as: kubectl!, docker, ect.
3. On the next screen, click Next: Configure Instance Details.
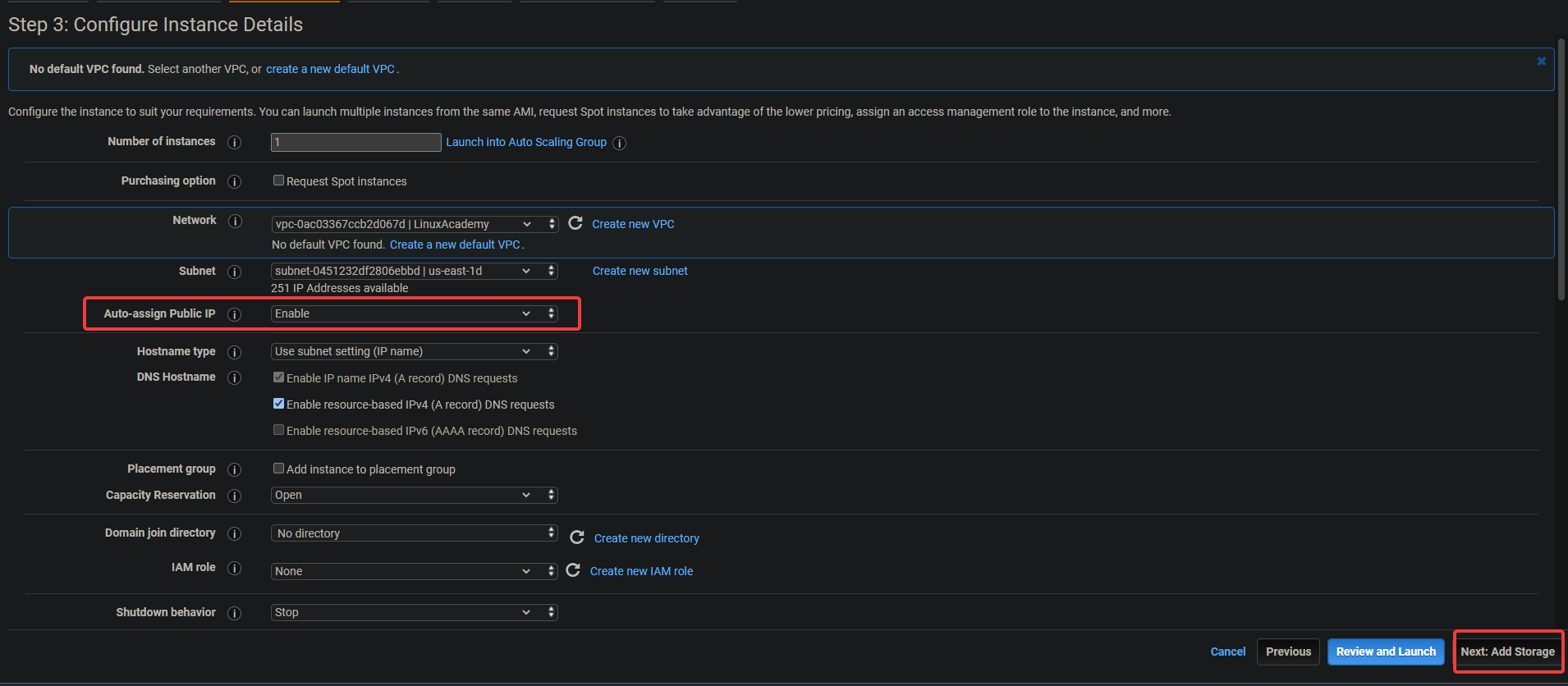
3. On the next screen, enable the Auto-assign Public IP option. Since the server is inside a private subnet, it won’t be accessible externally. You can give your servers public IP addresses by associating an Elastic IP address with the instance. By doing this, your EC2 and ELK is accessible. Click on Next: Storage.
3. On the next screen, click on Next: Add Tags > Next: Configure Security Group.
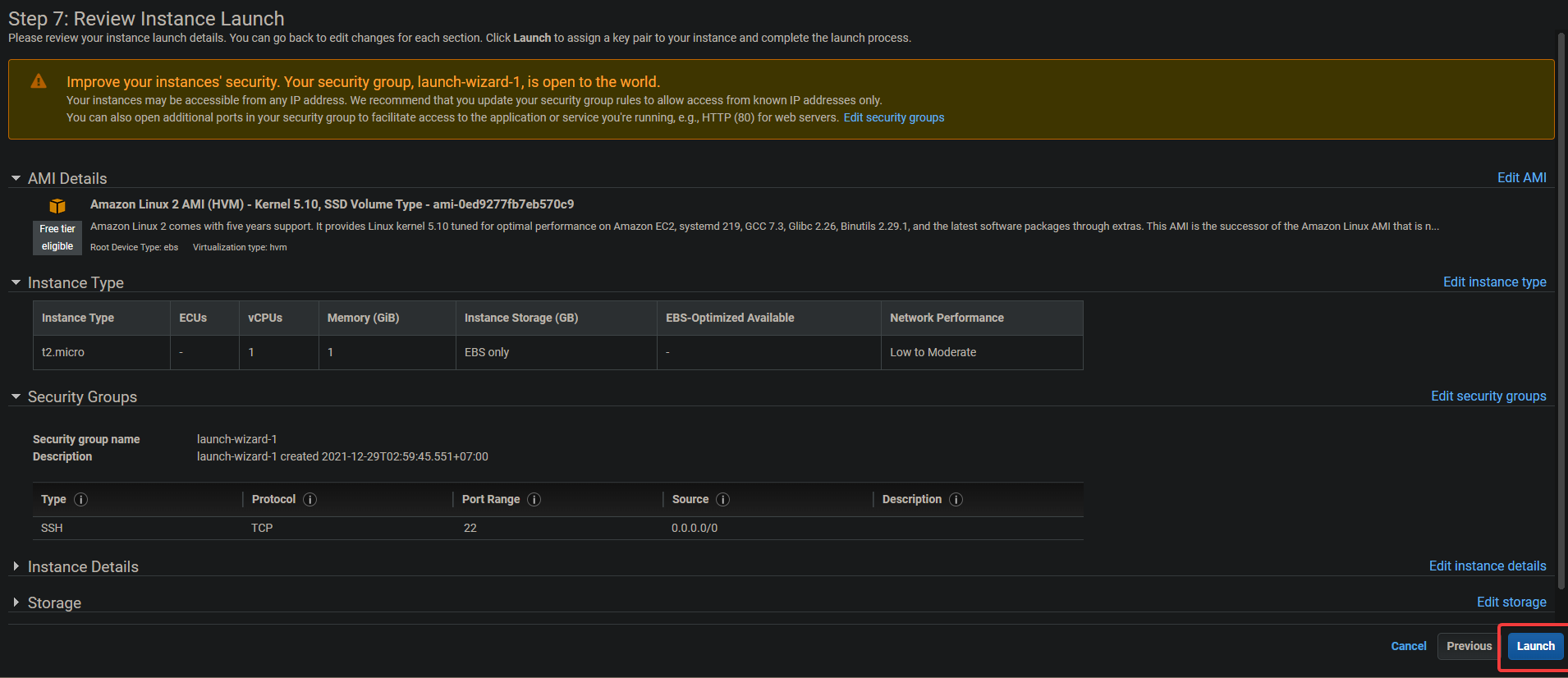
4. On the next screen, click on Review and Launch > Launch.
5. A key pair dialog will appear. Hit Create a new key pair. Give it a name, then download and store the .pem file in a secure location. Click Launch instance.
Configuring the Command Line Tools
Now that you have created an EC2 instance, you need to install the client for it. In AWS terms, a client is a command-line tool that allows you to manage cloud objects. In this section, you will learn how to configure the Command Line Interface (CLI) tools.
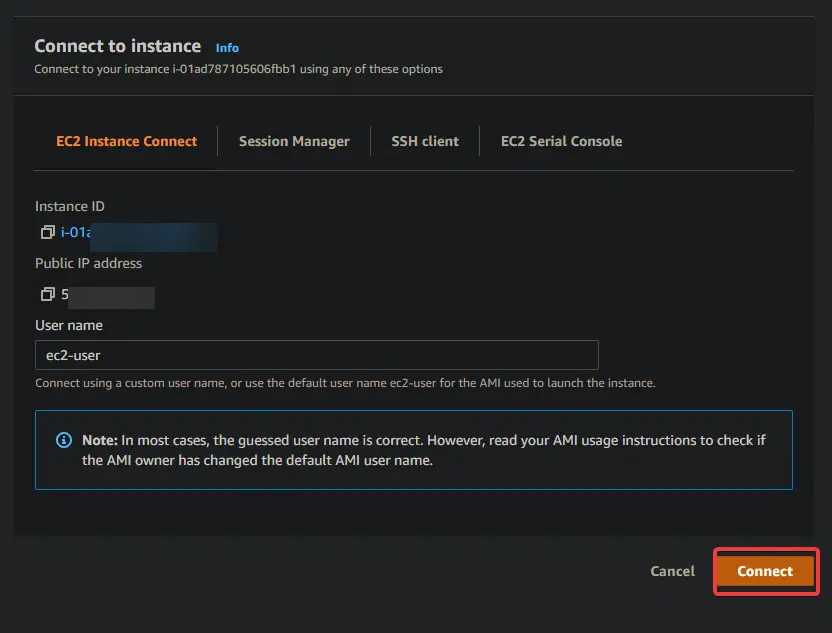
1. Navigate to your EC2 dashboard. You should see your new EC2 instance running. If not, your instance might take its first boot, wait 5 minutes and try again. Once your instance is running, click Connect.
2. On the next screen, click on Connect.
You will be taken to an interactive SSH session on your browser. SSH allows you to securely connect and operate on a remote server. The interactive SSH session will let us install the command line tools for EKS and Kubernetes directly onto your EC2 instance.
Once you log in the SSH session, the first thing you will need to do is to check for your aws-cli version. This is to make sure that you are using the latest version of AWS CLI. The AWS CLI is used to configure, manage and work with your cluster.
If your version is outdated, you may encounter some problems and errors during the cluster creation process. If your version is below 2.0, then you will need to upgrade it.
3. Run the following command to check your CLI version.
aws --version
As you can see in the output below, we are running version 1.18.147 of aws-cli, which is very out of date. Let’s upgrade the CLI to the latest available version, which is v2+ at the time of writing this.
4. Run the command below to download the latest available version of AWS CLI to your EC2 instance. curl will download your file from the given url, -o will name it as you choose, and “awscli-exe-linux-x86_64.zip” is the file to be downloaded
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
5. Once it finishes downloading, run the command below to extract the contents of your downloaded file to the current directory.
unzip awscliv2.zip
6. Next, run the which aws command to set your link for the latest version of AWS CLI. This command will let you know where in your environment’s PATH it can be found, so that you can run it from any directory.
which aws
As you can see in the output below, the outdated AWS CLI is located at /usr/bin/aws.
7. Now you need to configure your aws-cli by running an update command with some parameters. The first parameter ./aws/install will help us install AWS CLI to the current directory. The second parameter –bin-dir tells where in your environment’s PATH the AWS CLI will be located, and the third parameter –install-dir is a path relative to bin-dir. This command will ensure that all of your paths are up to date.
sudo ./aws/install --bin-dir /usr/bin --install-dir /usr/bin/aws-cli --update
8. Rerun the aws –version command to make sure that you are using the latest version.
aws --version
You should see the currently installed AWS CLI version. As you can see in the output below, we are now using v2.4.7 of AWS CLI. This is the latest version and will not give you any problems while configuring the next steps.
9. Now that your environment is configured properly, it’s time for you to configure which AWS account you want to communicate with through the AWS CLI. Run the following command to list your currently configured account environment variables with the alias you want to use along with it.
aws configure
This will show you all of your AWS account environment variables that are currently configured. You should see something like this in the output below. You need to set up some configuration parameters in order for the AWS CLI to communicate with your necessary accounts. Run the command below, which will take you through a configuration wizard to set up your AWS account.
- AWS Access Key ID [None]: Enter the AWS access key that you noted earlier.
- AWS Secret Access Key [None]: Enter the AWS Secret Access Key that you noted earlier.
- You also need to specify the default region name where your EKS cluster will be. You should choose an AWS region where your desired EKS cluster will be and which is closest to you. In this tutorial, we chose us-east-1 due to its geographical location close to us and ease of use for the next steps in the tutorial.
- Default output format [None]: Enter json as your default output format because it will be very useful for us to view the configuration files later.
Now that you have set up your AWS CLI tools. It’s time to configure the Kubernetes CLI tool named kubectl in your environment so that you can interact with your EKS cluster.
Kubectl is the command-line interface for Kubernetes. With Kubectl, you can manage applications running on Kubernetes clusters. Kubectl is not installed by default on Linux and MacOS systems. You can install Kubectl on other systems by following the instructions on the Kubernetes website.
10. Run the command below to download the kubectl binary. A binary is a computer file with the extension “.bin”, which is executable only on certain types of computers. It’s an easy way for disparate types of computers to share files. We use kubectl binary because the kubectl binary is platform agnostic. It will work on any system that can run a Unix-like operating system, including Linux and Mac OS.
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.16.8/2020-04-16/bin/linux/amd64/kubectl
11. Run the chmod command below to make the kubectl binary executable. The chmod command is a Unix and Linux command used to change file or directory access permissions. The Linux chmod command uses the octal numeral system to specify the permissions for each user. Kubectl can now be used on your local machine.
chmod +x ./kubectl
12. Run the command below to create a kubectl directory in your $HOME/bin folder and copy the kubectl binary to it. The mkdir -p $HOME/bin command creates a bin sub-directory inside your home directory. The mkdir command is used to create new directories or folders. The -p option tells the mkdir command to automatically create any necessary parent directories for the new directory. The $HOME/bin is an environment variable that stores your home directory path. Every Linux user has the $HOME/bin directory in their file system. The && construct is called a logical AND operator. It is used to group commands together so that more than one command can be executed at once. The && construct is not necessary for this command to work, but it’s there as a best practice.
The cp ./kubectl $HOME/bin/kubectl command copies the local kubectl binary file into your kubectl directory and renames the file to kubectl. Finally, the export command does what it says – it exports an environment variable into the shell’s memory so that it can be used by any program run from this shell. In our case, we need to tell kubectl where our kubectl directory is so that it can find the kubectl binary.
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin
13. Run the kubectl version command below to verify kubectl is installed correctly. The kubectl version –short –client command outputs a shortened version of the kubectl version in a well-formatted, human-readable Kubernetes REST API response. The –client option lets kubectl print the formatted version of Kubernetes’ REST API response, which is consistent across versions.
The –short option tells kubectl to provide basic information in a compact form with one decimal place for floats and an abbreviated time format that is the same as –format. You should see an output like the one below. This output tells us that we have successfully installed kubectl, and it’s using the correct version.
The last thing you need to do in this section is to configure the eksctl cli tool to use your Amazon EKS cluster. The eksctl cli tool is a command-line interface that can manage Amazon EKS clusters. It can generate cluster credentials, update the cluster spec, create or delete worker nodes and perform many other tasks.
14. Run the fololowing commands to install the eksctl cli tool and verify its version.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp && sudo mv /tmp/eksctl /usr/bin
eksctl version
Provision an EKS Cluster
Now that you have your EC2 and the AWS CLI tools, you can now provision your first EKS Cluster.
1. Run the eksctl create cluster command below to provision a cluster named dev in the us-east-1 region with one master and three core nodes.
eksctl create cluster --name dev --version 1.21 --region us-east-1 --nodegroup-name standard-workers --node-type t3.micro --nodes 3 --nodes-min 1 --nodes-max 4 --managed
The eksctl create cluster command creates an EKS Cluster in the us-east-1 region using the defaults recommended by Amazon for this specific configuration and passes all arguments in quotes ( ” ) or as variables ( ${ } ) accordingly.
The name parameter is used to define the name of this EKS Cluster and it’s just a friendly label for your convenience. version is the version you want the cluster to use, for this example, we will stick to Kubernetes v1.21.2 but feel free to explore other options as well.
nodegroup-name is the name of a node group that this cluster should use to manage worker nodes. In this example, you will keep it simple and just use standard-workers which means your worker nodes will have one vCPU and 3GB of memory by default.
nodes is the total number of core worker nodes you want in your cluster. In this example, three nodes are requested. nodes-min and nodes-max control the minimum and maximum number of nodes allowed in your cluster. In this example, at least one but not more than four worker nodes will be created.
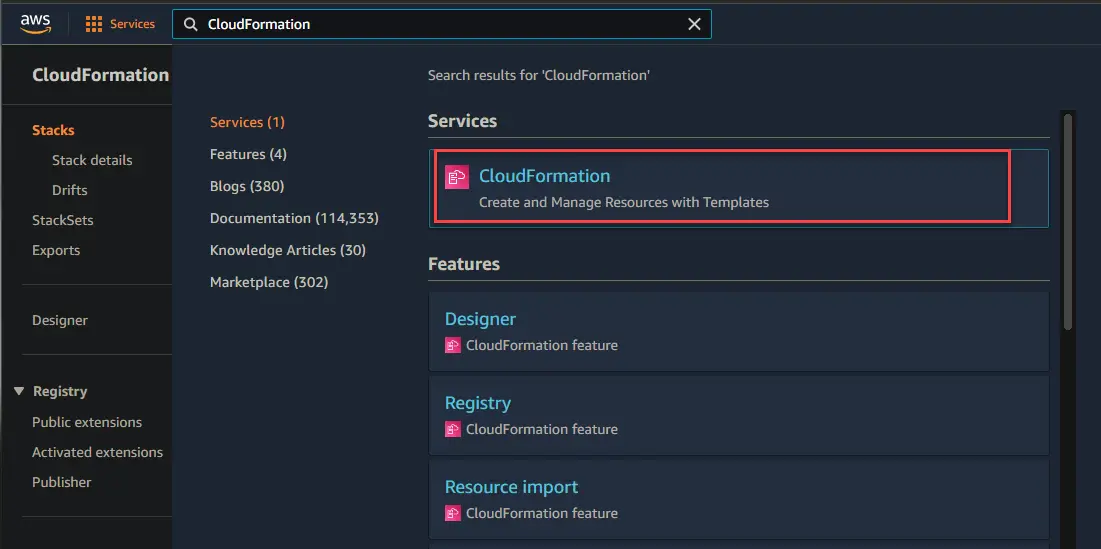
2. You can navigate to your CloudFormation console to monitor the provisioning progress.
As shown below, you can see that your dev stack is being created.
3. Click on the dev stack hyperlink > Event. You will see a list of events related to the creation process. Wait for the provisioning process to complete – this can take up to 15 minutes depending on your specific circumstances – and check the status of the stack in the CloudFormation console.
4. After you wait for the stack to finish provisioning, navigate to your CloudFormation console, you will see your dev stack status of CREATE_COMPLETE.
Now, navigate to your EC2 console. You will see one master node and three core nodes in the EC2 Dashboard. This output confirms that you are set up the EKS cluster successfully.
5. Run the eksctl command below to get the details of the dev cluster, such as cluster-ID and region.
eksctl get cluster
6. Run the aws eks update command below to get the remote worker node credentials. This command must be executed on any computer you want to connect to the cluster. It downloads credentials for your kubectl in order to access EKS Kubernetes Cluster remotely, without using AWS Access access keys.
aws eks update-kubeconfig --name dev --region us-east-1
Deploying your Application on the EKS Cluster
Now that you have your EKS Cluster provisioned. Let’s deploy your first application on your EKS Cluster. In this section, you will learn how to deploy an nginx web server along with a load balancer as a sample application.
1. Run the command below to install git on your system. You will need git to clone the nginx web server code from GitHub.
sudo yum install -y git
2. Run the git clone command below to clone the nginx web server code from github to your current directory.
git clone https://github.com/ata-aws-iam/htf-elk.git
3. Run the cd htf-elk command to change the working directory to the nginx configuration files directory.
cd htf-elk
4. Run the ls command to list files in the current directory.
ls
You will see the following files present in your nginx directory.
5. Run the cat command below to open the nginx-deployment.yaml file and you will see the following contents present in that file.
cat nginx-deployment.yaml
- apiVersion: apps/v1 is the core Kubernetes API
- kind: Deployment is the kind of resource that will be created for this file. In a Deployment, a Pod is created per container.
- metadata: specifies metadata values to use when creating an object
- name: nginx-deployment is the name or label for this deployment. If it has no value, the deployment name is taken from the directory name.
- labels: provides labels for application. In this case, it will be used for service routing via Elastic Load Balancing (ELB)
- env: dev describes an environment variable that is defined by a string value. This is how you can provide dynamic configuration data to your container.
- spec: is where you define how many replicas to create. You can specify the properties on which you want each replica to be based.
- replicas: 3 will create three replicants of this pod on your cluster. These will be distributed on the available worker nodes that match the label selector .
- containerPort: 80 will map a port from the container to a port on the host. In this case, it will map port 80 on the container to port 30000 of your local machine.
6. Run the cat command below to open the service file nginx-svc.yaml. You will see the following contents present in that file.
cat nginx-svc.yaml
7. Run the kubectl apply command below to create the nginx service in your Kubernetes Cluster. It will take a few minutes for the EKS cluster to provision ELB for this service.
kubectl apply -f ./nginx-svc.yaml
8. Run the kubectl get service below to get the details about the nginx service you just created.
kubectl get service
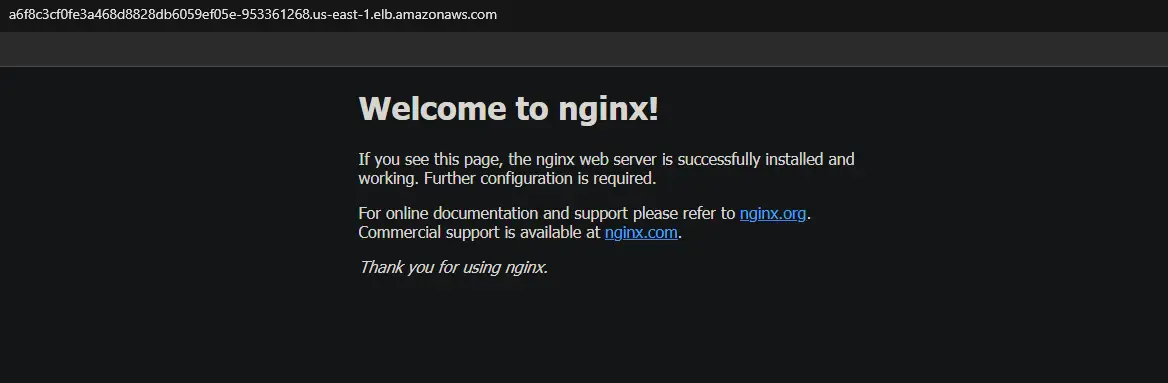
You will get the following output. ClusterIP is the internal kubernetes IP assigned to this service. The LoadBalancer ELB name is a unique identifier for this service. It will automatically create an ELB on AWS and provision a public endpoint for this service that can be reached by services of your choice such as web browser (Domain Name) or API clients. It is accessible through an IP address of your choice.
Load Balancer ELB with name a6f8c3cf0fe3a468d8828db6059ef05e-953361268.us-east-1.elb.amazonaws.com has port 32406, which will be mapped to the container port 80. Note down the DNS hostname of the load balancer ELB from the output; you will need it to access the service later.
9. Run the kubectl apply command below to apply the deployment for your cluster.
kubectl apply -f ./nginx-deployment.yaml
10. Run the kubectl get deployment to get the details about the nginx deployment you just created.
kubectl get deployment
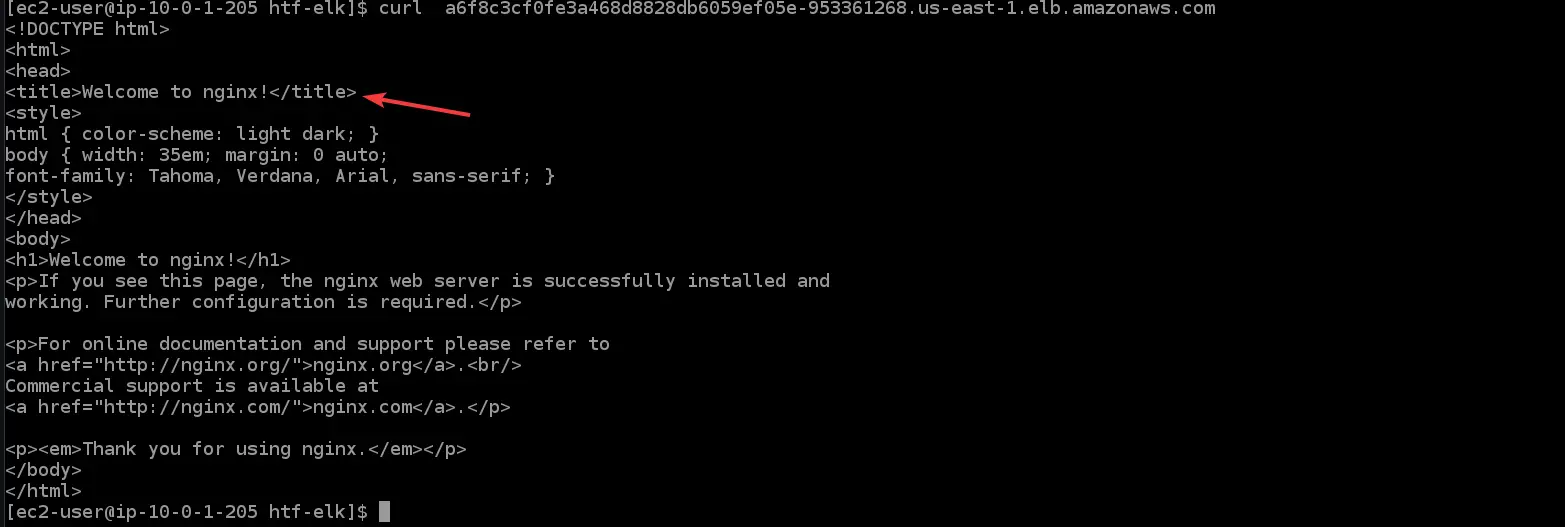
11. Run the command below to access your nginx application through the load balancer. You will see the welcome page from nginx in your terminal/console, which confirms that your nginx application is working as expected. Replace <LOAD_BALANCER_DNS_HOSTNAME>with the DNS hostname of the load balancer you noted above.
curl "<LOAD_BALANCER_DNS_HOSTNAME>"
12. You can also access your nginx application through the browser by copy and pasting the load balancer DNS hostname into the browser.
Verifying the Highly Available(HA) Feature for Your Cluster
Now that you have created your cluster successfully, you can test the HA feature to ensure it works as expected.
Kubernetes supports multi-nodes deployments with the use of special controllers that work in tandem to build and manage replicated pods or services. Some of these controllers are Deployments, ReplicationController, Job and DaemonSet.
A deployment controller is used to control replication on pod or service level. When your pod is out of resources, it will delete all pods of that replication controller (except the one which is running on master node) and create new replicas of this pod. This will help you get a very high up-time across your applications.
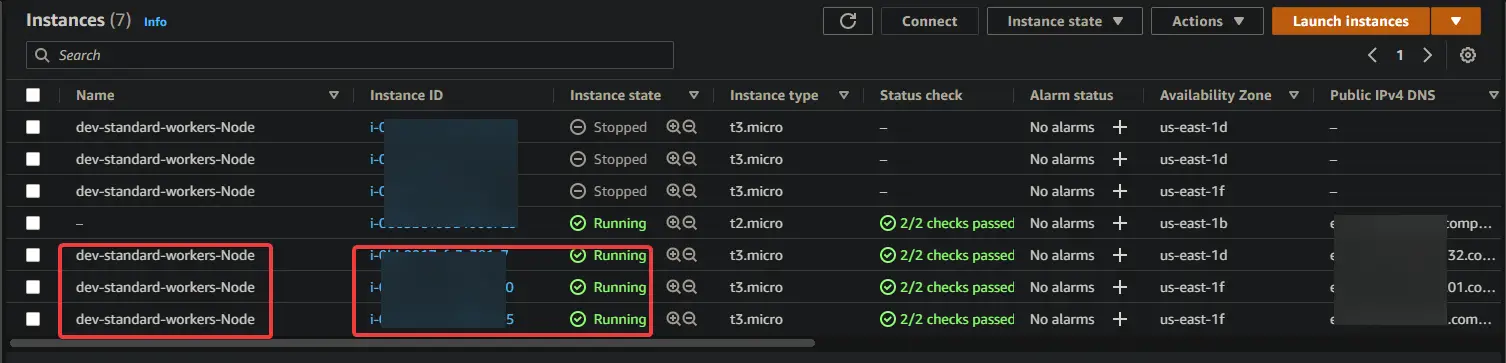
1. Navigate to your EC2 dashboard and stop all three worker nodes.
2. Run the command below to check the status of your pods. You will get different statuses: Terminating, Running, and Pending for all your pods. Because once you stop all the worker nodes, EKS will try to restart all the worker nodes and pods again. You can also see some new nodes, which you can identify by its age(50s).
kubectl get pod
It takes some time to boot up the new EC2 instance and pods. Once all worker nodes are booted up, you will see all the new EC2 instances come back to Running status.
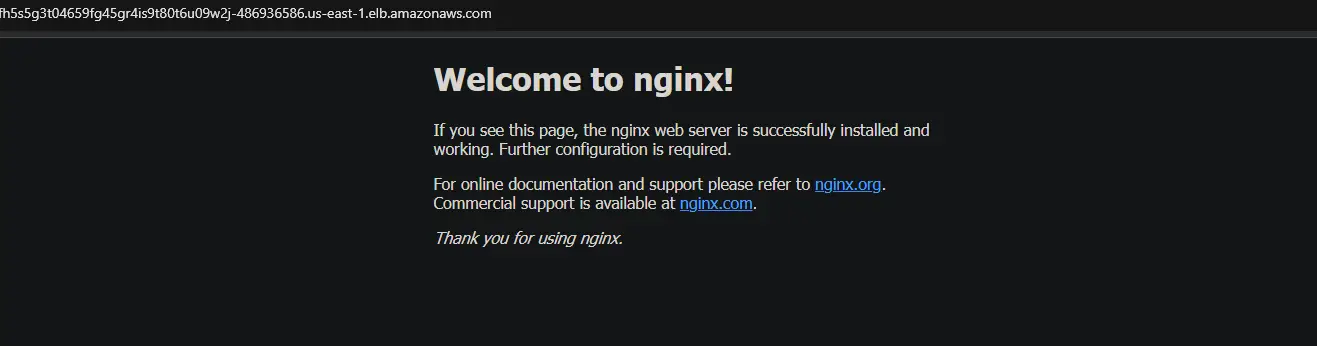
3. Rerun the kubectl get service again. You can see that ESK will create a new nginx service and a new DNS name for your load balancer.
kubectl get service
Copy and paste the new DNS into your browser. You will get the welcome from the Nginx page again. This output confirms that your HA works as intended.
Conclusion
In this article, you learned how to set up your EKS cluster. You also verified that the Highly Available Feature works by stopping all of your worker nodes and checking the status of your pods. You should now be able to create and manage EKS clusters using kubectl.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Add Comment